Guidance and best practices for content IDs
Content IDs refer to the set of identifiers that an application can use to refer to content assets mapped into an adaptive course and made known to Knewton via graph ingestion or a partner’s content inventory. These references can be used throughout the API whenever an application defines goals (namely, when specifying a goal’s target and recommendable modules), sends events, or requests recommendations and analytics.
Unlike UUIDs associated with resources created by Knewton (e.g. registrations, accounts, goals) and generated dynamically every time a new resource is created via the Knewton API, content IDs are generated based on partner’s own content identifiers or labels. This ensures that the same piece of content can be referenced by the same content ID across environments (when mapped into multiple development environments), and graphs (when included in multiple graphs).
The way content IDs are generated from partner’s own content identifiers and labels allows partners to “know” the future content ID just by knowing a content’s identifier or label on their side. Partner ID to content ID mapping rules are defined below.
Note: Partners must ensure that the same IDs are not reused for multiple pieces of content. Each unique piece of content on the application side must have its own unique ID. If new content assets are added, they should be assigned new partner identifiers such that distinct content IDs can be generated by Knewton. This also means that once an ID is assigned to a given piece of content, it should not be reused for a different type of content asset even if the original one is removed (e.g. reusing what was an Atom ID as a Container ID and vice versa).
Three types of content identifiers are associated with every graph:
All of these are included in the graph spreadsheet after ingestion. A portion of the sample spreadsheet showing Modules sheet:
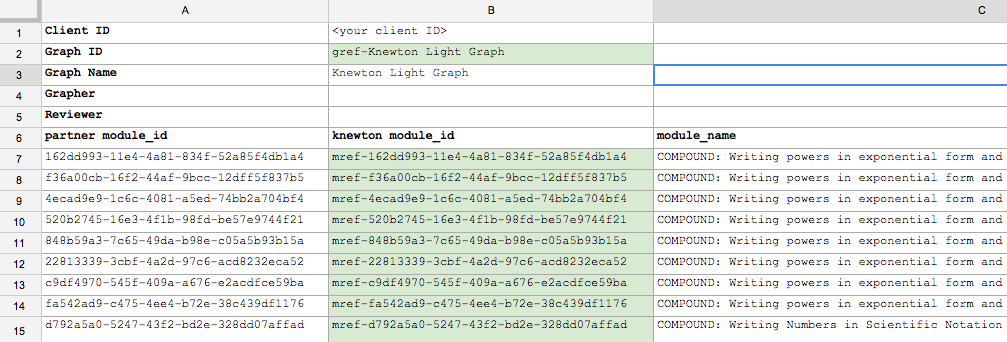
Figure 1: Graph content IDs and module content IDs are part of the graph spreadsheet (highlighted in green; Modules sheet)
The first highlighted ID is the graph’s content ID, which the application passes in when creating a learning instance. A graph with the same content ID can be ingested into multiple environments, so the part of the application that creates learning instances can remain independent of which environment the application is deployed against.
The other highlighted IDs are module IDs. Each module ID corresponds to a unique partner module ID. Assuming the application uses a CMS, partner identifiers are just asset identifiers used by the partner’s CMS. Each line of the spreadsheet corresponds to a unique content asset, but the same content asset can be included in multiple content inventories or graphs. Naturally, it would then have the same partner ID, which will in turn be mapped to the same content ID.
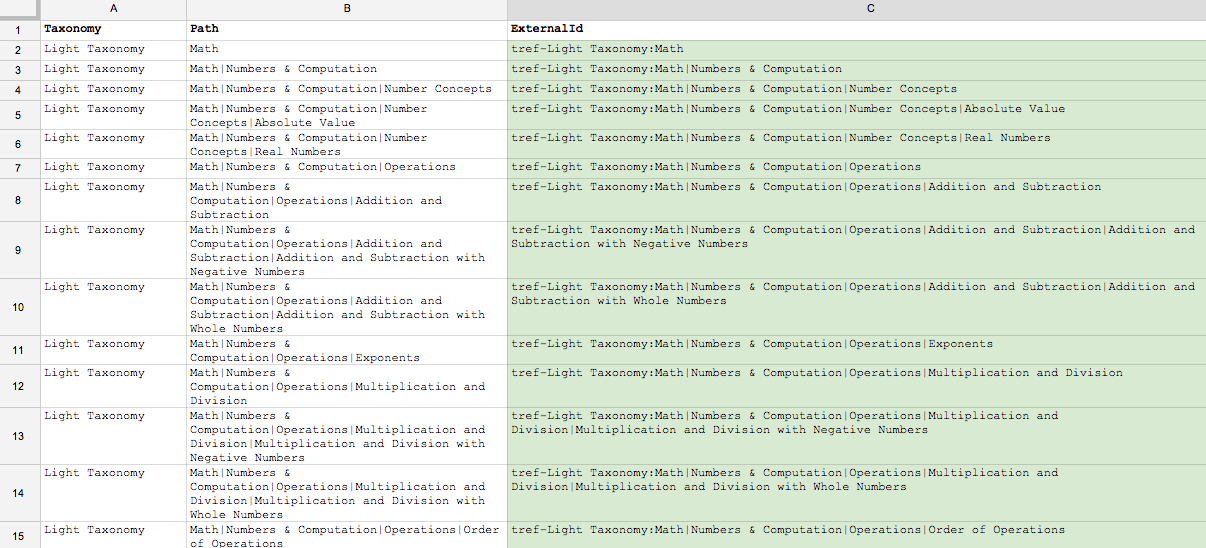
Figure 2: Taxon content IDs are part of the graph spreadsheet (highlighted in green; Taxonomy UUIDs sheet)
The highlighted content IDs are the taxon content IDs. The application uses these IDs when defining goals.
<Partner Graph Name> => "gref-" + <Partner Graph Name> (e.g. “Knewton Light Graph” becomes “gref-Knewton Light Graph”)<Partner Module ID> => "mref-" + <Partner Module ID> (e.g. “1928” becomes “mref-1928”)<Partner Taxon Name> => "tref-" + <Partner Taxonomy Name> + ":" + <Full Taxon Path><Partner Taxon Name> (e.g. “Section1” becomes “tref-TOC:Ch3|Section1”)<Partner Learning Objective ID> => "lref-" + <Partner Learning Objective ID> (e.g. “lo4832” becomes “lref-lo4832”)Examples:
my-“-module)my-module\)