Powering adaptive experiences with recommendations
 See our recommendations api specs for more on integrating recommendations into your application.
See our recommendations api specs for more on integrating recommendations into your application.
In this section:
The Knewton API returns a set of recommended modules (and related, contextual information described below) for use within adaptive learning experiences in partner applications. Recommendations guide learners toward the completion of goals. Recommendations can be used to implement a wide range of pedagogical approaches to ensure a learner advances as efficiently as possible toward achievement of the goal’s completion criteria.
A recommendation takes into account all of the learning application data Knewton analyzes, including an individual’s ongoing work, content alignment and difficulty parameters, goal structure, and one of several pedagogies designed to bring about meaningful changes to the learner’s knowledge state. In an adaptive learning experience, recommendations may play the role of a tutor in selecting formative questions and instructional interventions for an individual student in real time. After retrieving a recommendation, partners can deliver the recommended content and display the recommendation’s contextual information within their application in whichever way is most appropriate for the application’s design.
Many factors go into calculating recommendations for a specific learner.
adaptive_behavior and other fields set on the goal. Each adaptive_behavior maps to a context-specific pedgagogy impacting how recommendations are chosen, including whether instructional engagement is required at the beginning of the assignment, whether frequent interleaving between targets is desirable, and the degree to which just-in-time prerequisite support is appropriate. For more details on the pedagogical ramifications of adaptive_behavior, refer to the goal implementation guide.By creating well-targeted goals, partners and/or instructors can exert control over the recommendations learners receive. The Knewton Data Science team engages continuously with learning science research to optimize the fit of Knewton recommendations pedagogy to different content structures and stages of a learner’s journey to content mastery.
Alongside the list of recommended modules, the Knewton API can also provide contextual information in the form of a “justification” for the top recommendation in the list, if requested. A recommendation’s justification consists of metadata about the recommended content’s alignment in the knowledge graph and the reason for its selection.
intent field meant to convey the pedagogical purpose of the recommendation.For field-level details about justifications, see the justifications API reference. For recommended uses of justifications, see Using Recommendations below.
When a learner struggles with a target learning objective, Knewton attempts to support the learner by recommending easier questions, instructional modules, and/or remedial content, if available for the goal in question. But in some cases, either these materials are unavailable or the student has exhausted them without achieving success. In these cases, Knewton recommendations will include a stuck: true field that partners may use to cue manual interventions or instructor notifications. Knewton will continue to provide recommendations when a learner is stuck, but partners products may opt to use this signal to trigger some other form of intervention.
Partner applications may request and use recommendations in a variety of ways. The most common and effective usage pattern is to use recommendations to structure an adaptive learning experience where the partner application displays one recommended module at a time to the learner. Once the learner engages with the module, the partner application submits any relevant events to the Knewton API and requests a new recommended module. Within this flow, requested justification fields may be displayed to the learner alongside modules, as well as any relevant goal-specific analytics.
Alternately, a partner application may provide several recommended modules as options from which a learner will choose. In these contexts, the recommendations will be most relevant if the partner application requests a new recommendation from the Knewton API after each question the learner chooses and answers. It is possible to display several questions sequentially (either as a large “bundle” or as several modules in a row) to a learner before requesting a new recommendation, but this degrades the quality of Knewton’s adaptivity. Item-by-item recommendations should be preferred.
The Knewton API returns a prioritized list of recommendations with each request. While the top module on the list is Knewton’s strongest recommendation and comes with justifications, the remainder of the recommended modules list provides flexibility to partners and enables them to provide a seamless experience to the learner irrespective of complicating factors such as connectivity failures, latency requirements in their application, or temporary content unavailability in their content management system.
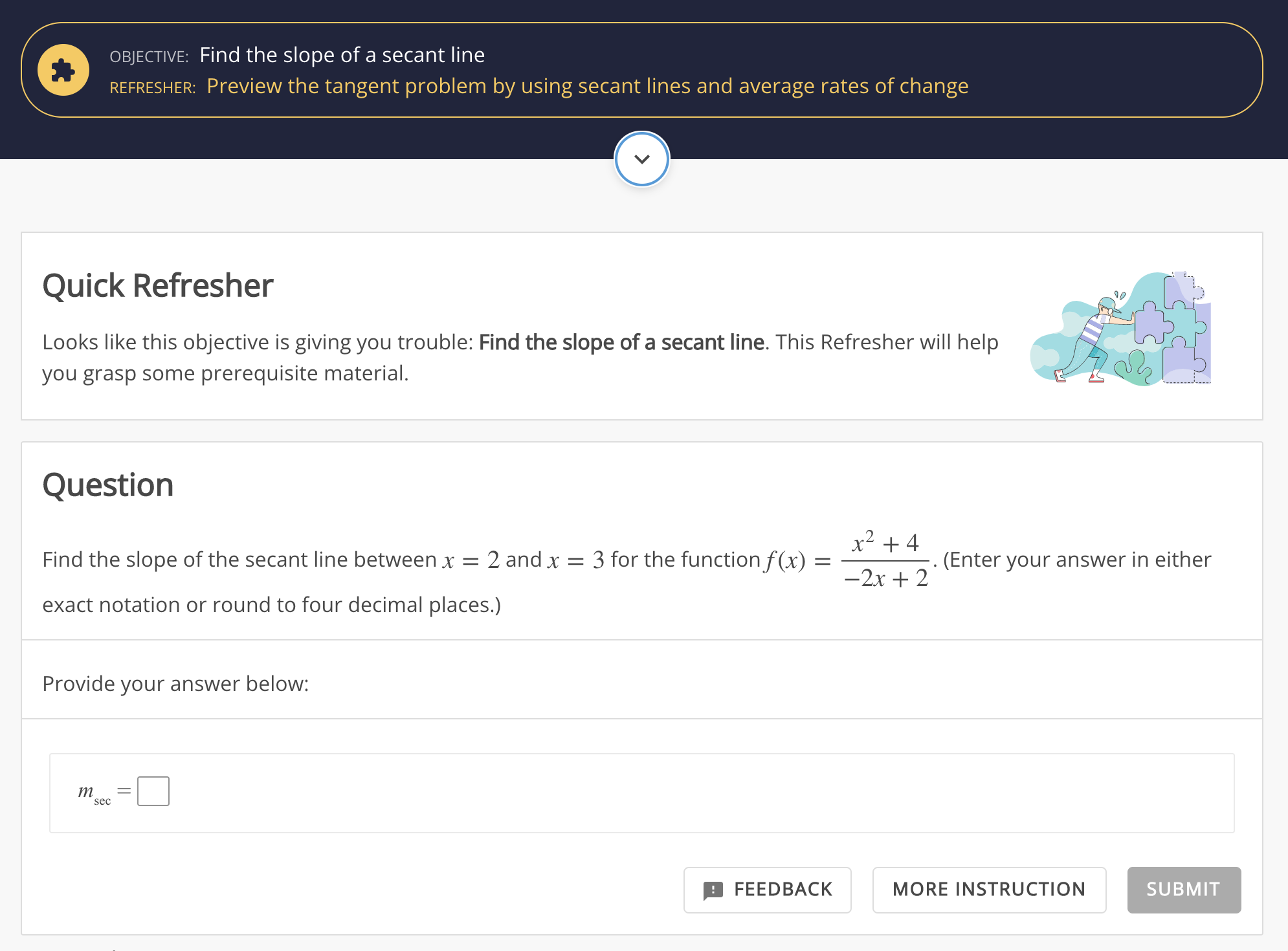
Once a partner application receives a recommendation from the Knewton API, the application typically fetches the top recommended module from the application’s content management system and displays it to the learner. As in the screenshot below, the application may also opt to use justification fields to contextualize the recommendation by indicating which learning objective the module teacher or assesses (in this example, “Preview the tangent problem by using secant lines and average rates of change”) and why that learning objective has been chosen (here, because the student is struggling with the learning objective “Find the slope of a secant line”).
An algorithmic question is an assessment atom where one or more parts can be dynamically or “algorithmically” generated. For example, instead of having separately graphed assessment items for the questions “3 + 5 = ?”, “8 + 2 = ?”, “4 + 7 = ?”, and so on, the partner can have a single algorithmic module in the knowledge graph, where the learner adds two single-digit numbers, and those numbers are dynamically generated by the partner application. An alternative approach to dynamically generating questions is grouping a number of pre-created variants of a question together into a “pool”, and the question pool, rather than each of its variants, is included in the knowledge graph as a single module. For more information on defining algorithmic questions, see Algorithmic Questions under Best Practices for Adaptive Content.
When Knewton recommends an algorithmic question, it does not recommend a particular variant; it is the partner application’s responsibility to pick which algorithmic variant will be shown. Partners typically choose to display the most novel variant available, if an explicit pool of variants exists, or may generate the variant based on timestamps or other forms of randomization.
The Knewton API considers each variant of an algorithmic question an “instance”. When a graded event is sent after the algorithmic question is completed by the learner, the ID of the chosen instance should be included in the graded event as the instance_hash. See Sending Events for more information. The recommendations engine uses this information, when available, to accurately assess the number of unique questions a student has answered.
Getting Started
Working with Adaptive Assignments
Predictive Learner Analytics
General API Usage
Brand Guidelines
Glossary